Transforming analytical functions by mainstreaming data science
In government and beyond, organisations are aiming to become more data driven. The widespread adoption of data science approaches throughout analytical teams is key to achieving these aims. However, the value of data science is often understood too narrowly, and a misplaced focus can cause businesses to miss out on the most significant benefits.
This post describes how data science provides a new approach to tackling analytical problems. This approach can be used by all analysts, and results in a sustained increase in efficiency, quality of analysis, impact, and the pace of analytical innovation. I call it post-hype data science.
A new approach to analytical projects
For me, data science boils down to applying the most powerful tools, techniques and ways of working to solve analytical problems. Most of the value comes from applying new ways of working and better tools to traditional problems, rather than through the application of the cutting edge techniques like machine learning and neural networks, which are sometimes seen as synonymous with data science.
If data science is really just a new way of working, what explains its dramatic rise in recent years? It’s a consequence of a rapid and radical improvement in the analysts’ toolset, which enable this new workflow. Free and open source tools like R and Python are now the most popular tools used by data scientists, and are some of the world’s fastest growing programming languages. ‘Social Coding’ tools like Github, which greatly facilitate collaboration between analysts who may never have met in person, have become enormously more popular in the last decade.
Across multiple disciplines, analysts are finding that these tools can lead to radically different ways of working. For instance, in academia, the reproducibility crisis is leading academics to question the traditional approach to publishing papers, and a leading economist has recently said that open source data science tools are “well on the way to becoming a standard for exchanging research results¹.”
What does this mean for the future of analytical work?
Consequence 1: New ways of working unlock time for analysts to develop more insight, and enable them to respond faster as business questions change
For an analytical result to be useful, we need to know three things:
- What is the analytical result and why is it important?
- What methodology did we use and how do we know we can trust it?
- Why did we choose this methodology versus alternatives?
Historically, analysts have solved these problems with a customer-facing write up, a technical write up, and a quality assurance log — standalone documents written mainly in prose. The analysis itself has been conducted separately, most often in Excel and VBA. This package of documents underpins Analytical Quality Assurance (AQA), and is also essential for corporate knowledge retention.
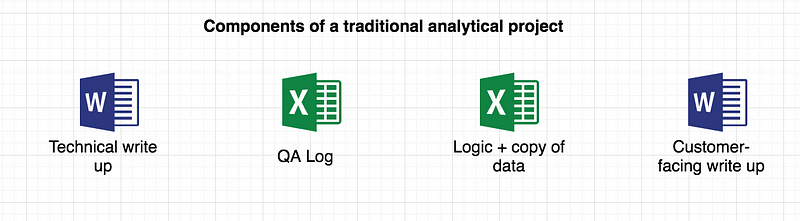
This approach works, but it is time consuming, and difficult to iterate. Each element needs to be updated or recreated as things change, and we risk the documents getting out of sync with each other. Since copies of data are often embedded in the same spreadsheet as the main logic, the code cannot be shared widely for data security reasons, resulting in analytical projects being held in silos.
The approach taken by data scientists is different. We believe that the most precise and succinct statement of a method is computer code which, when run, transforms the ‘raw materials’ (data and assumptions) into an analytical result.
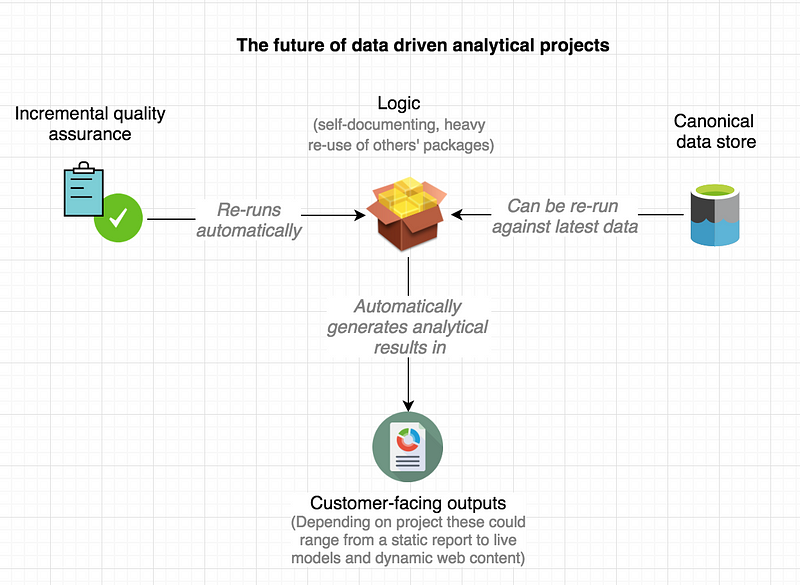
This new way of working is an improvement because:
- It’s fully reproducible, and therefore easy to subject to peer review because the methodology is fully verifiable. Data provenance and processing logic is clear.
- Data is read directly from canonical data stores rather than being copied, and results can be updated at the click of a button if a newer dataset becomes available. This simplifies the problem of data management, and brings organisations closer to having a ‘single version of the truth’.
- It enables automated approaches to quality assurance which can be written incrementally over the lifetime of the project, and which are run every time the project is changed — known as ‘unit tests’. These enable rapid iteration. Because unit tests can be automatically re-run in the future, the quality assurance status of the project is clear, and this opens the door to future re-use of the code.
- Well written code is succinct and mostly self documenting. The technical write up can no longer fall out of sync with the model because they are not two independent things. Where documentation is required, we can use literate programming to ensure it keeps in sync with the logic.
- By using version control tools like Github, we can automatically store large amounts of information about how and why the code was developed. For instance, the project’s ‘to do’ list or roadmap can be directly linked to changes in the code itself, reducing ambiguity about what decision were made, why and when. Version control provides a host of other benefits. Self-documenting, version controlled code helps enormously with corporate knowledge retention.
- Since code and data are separate, we can share the code widely, including on the open internet, whilst protecting potentially sensitive data. Colleagues can easily search and discover historical projects.
By enabling much faster iteration with greater confidence of quality, analysts can deliver more relevant evidence faster.
This new workflow also enables analysis to be embedded more widely in organisations — into situations where speed is critical. For example, operational decision makers often data to be up-to-date for analysis to be useful to them. This is only possible when the analytical process is fully automated and reproducible.
Consequence 2: Sharing and reuse will be the norm not the exception, reducing the complexity of our work whilst increasing its sophistication.
Data scientists’ heavier reliance on high-quality, reproducible code has unlocked an explosion in the sharing and re-use of analytical work. As data scientists, we have a tangible sense of being part of a worldwide community who are empowered to continuously improve our own tools. For example, there are now over 10,000 R ‘packages’ — reusable chunks of code and analysis, which can be downloaded and used for free².
Re-use is great for saving time, but some of the biggest benefits relate to its ability to help us manage complexity, create a better division of labour, and incrementally increase quality. By creating small, high quality code libraries which can be re-used in new analytical projects, analysts can quickly assemble these ‘lego blocks’ into powerful new results using surprisingly little code, which in turn makes new work easier to understand. Since these ‘lego blocks’ are re-used in multiple projects, any improvements can result in widespread benefits.
The result is a sustained increase in analytical innovation. We can continuously improve the quality and power of our models, rather than reinventing the wheel in different organisations or teams at different times³.
Making it happen
At an organisational level, the transition to new skills and ways of working is a huge challenge, and I may write about it separately.
However, as an individual analyst, one of the the most exciting things about data science is that the tools and high quality training materials are available online for free. Building a data science skillset requires time and dedication, but doesn’t necessarily need the kind of expensive classroom-based courses that are often needed for proprietary tools.
You can begin your journey by trying out some of the most powerful data science tools in your web browser by clicking this link⁴. You can find the cross government data science community’s list of free, high quality learning resource for Python and R here and here. What are you waiting for?
Endnotes
¹ To get a sense of the power of this software, you can run the analysis behind a recent Nobel Prize winning physics paper in a web browser with no special software here.
² We see this — for example — in the outstanding tidyxl package, which was written by Duncan Garmonsway at GDS.
³ You can read more about the benefits of coding in the open here.
⁴ May be blocked on some corporate IT systems, but will work at home or on your smartphone!